About
Working with some messy address or name data? It helps to split each one into separate components.
parserator is a framework for making parsers using natural language processing (NLP) methods.
There are currently two parsers available: usaddress for addresses and probablepeople for names.
What's a probabilistic parser?
Structured text like written addresses and names don’t have rules as much as they have tendencies. Instead of coming up with a set of hard and fast parsing rules, parserator takes a statistical approach to learn these tendencies from real examples.
For a given address or name, we use a statistical model, called conditional random fields, to find the sequence of fields that has the highest probability of generating it.
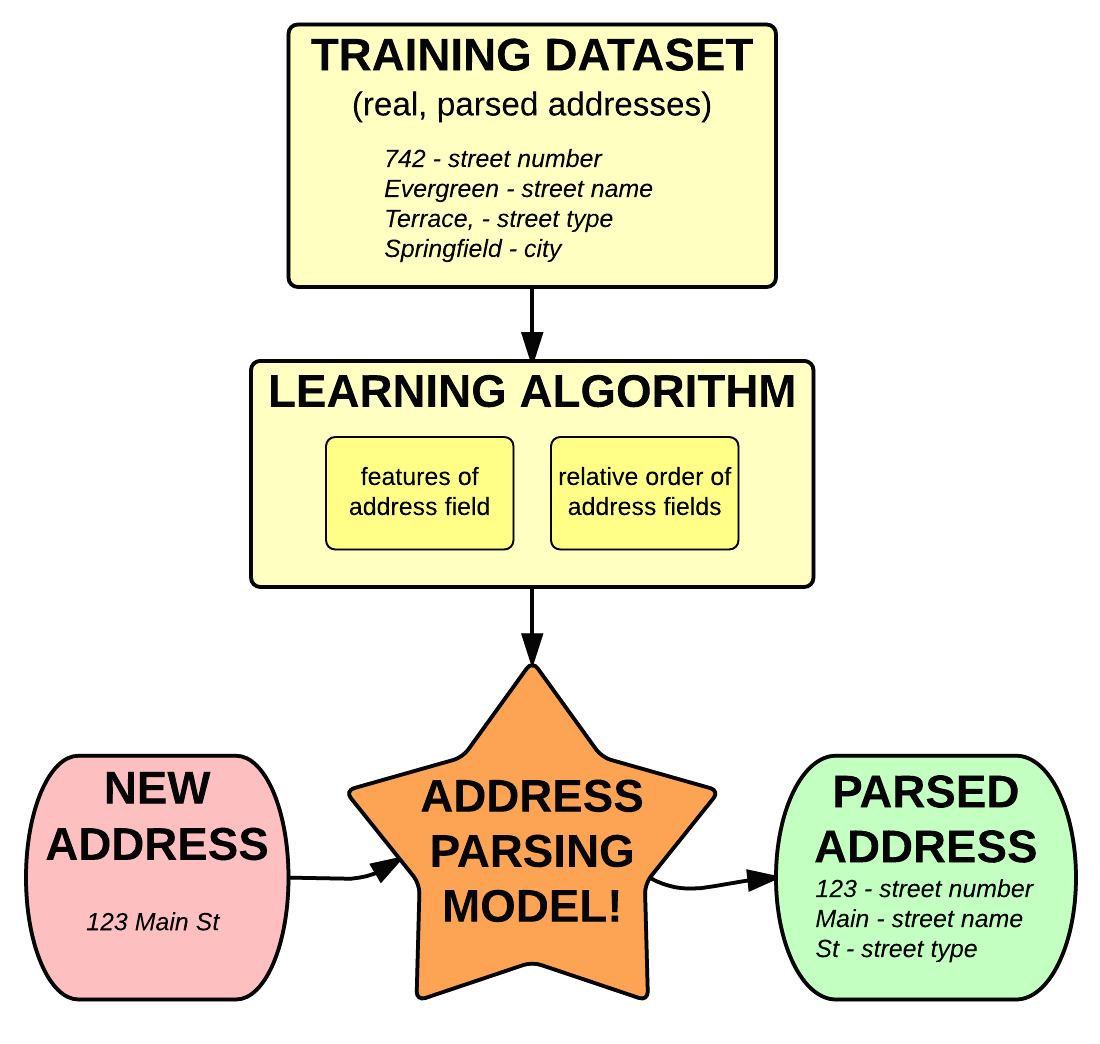
For more, read our blog posts on Parsing addresses with usaddress and Parse names and parse ... anything, really.
Who made this?
usaddress, probablepeople and the parserator framework were all built in partnership with the Atlanta Journal-Constitution and DataMade as part of the Entity-Focused Data System - a platform for journalists to continually link information about political figures, campaign filings, contracts and lobbyist disclosures to drive investigations.
We built everything open source under the MIT License so others could benefit from this work.
Contact us
Need help parsing a lot of addresses? Looking for guidance on creating your own parser? Contact DataMade.